
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 빅데이터
- topic
- Docker #도커 #이미지 #컨테이너 #리눅스 #Back-end
- hdfs
- Apache kafka
- hyper-v
- Jupyter notebook
- Django
- wsl2
- 하둡
- big data
- 이미지
- docker desktop
- docker-compose
- orchestration
- nginx
- hadoop
- container
- 도커
- Window 10
- Kafka
- 데이터 수집
- Dockerfile
- docker
- Today
- Total
개발자 일기장
[Apache Hadoop #1/하둡 개념정리] 본문
What is Apache Hadoop?
Apache Hadoop, High-Availability Distributed Object-Oriented Platform
- 대량의 자료를 처리할 수 있는 큰 컴퓨터 클러스터에서 동작하는 신뢰성 있고, 확장성 있는 분산 컴퓨팅을 위한 오픈소스 프레임워크
- 2005년 더그 커팅(Doug Cutting)과 마이크 캐퍼렐라(Mike Cafarella)가 개발
- 원래 너치의 분산 처리를 지원하기 위해 개발된 것으로, 아파치 루씬의 하부 프로젝트
- 간단한 프로그래밍 모델을 사용하여 대용량 데이터의 분산 처리를 할 수 있는 프레임워크
- 분산 파일 시스템 GFS, 분산 처리 시스템 MapReduce 소프트웨어 구현체
– 아파치 Top-Level 프로젝트
– 코어는 Java, C/C++, Python 등 지원 - 대용량 데이터 처리를 위한 플랫폼
– 분산파일시스템(HDFS)
– 분산병렬처리시스템(MapReduce)
– 기반소프트웨어프레임워크(Core)

하둡은 정형데이터 및 사진영상 등의 비정형 데이터를 효과적으로 처리하는 오픈소스 빅데이터 솔루션으로, 포춘 500대 기업 모두가 하둡을 활용하고 있을 정도로 업계에서는 ‘빅데이터가 곧 하둡’이라고 표현한다. 하둡관련 오픈소스 솔루션들은 해마다 발전하여 ‘하둡 에코시스템’이라 불리는 하둡과 연동된 하둡 생태계를 구성하여서 확장성을 넓혀 가는 중이다. 하둡은 간단한 프로그래밍 모델을 사용하여 여러 대의 컴퓨터 클러스터에서 대규모 데이터 세트를 분산 처리할 수 있게 해주는 프레임워크이며, 단일 서버에서 수천대의 머신으로 확장할 수 있도록 설계되었다. 일반적으로 하둡의 분산 저장 파일 시스템(HDFS)과 맵리듀스(MapReduce) 프레임워크를 의미하였으나, 아래 그림과 같이 여러 데이터저장, 실행엔진, 프로그래밍 및 데이터 처리 같은 하둡 생태계 전반을 포함하는 의미로 확장 발전되었다.
현재도 지속적으로 하둡 생태계가 확장되어가고 있는데, 이렇게 확장성이 뛰어난 이유는 하둡이 다른 모듈과 쉽게 연동되어 사용될 수 있도록 구성되어있기 때문인데, 이 글에서는 그중에서도 다른 프레임워크들과 가장 많이 연계되어 사용되는 HDFS에 대해서 소개하겠다.
Hadoop module
• Common
– 다른 하둡 모듈을 지원하는 유틸리티
• HDFS
– Hadoop Distributed File System
– 어플리케이션 데이터에 고성능 접근을 지원하는 분산 파일 시스템
• MapReduce
– 대용량 데이터의 병렬 처리를 위한 얀 기반 시스템
• YARN
– 잡 스케줄링과 클러스터 리소스 관리를 위한 프레임워크
• HBase
– 분산 데이터베이스
HDFS(Hadoop Distributed File System)는 아래와 같은 특징을 갖는다.
• 어플리케이션 기반 파일 시스템
• 파일의 분산 저장이 목적
• NameNodes와 DataNodes로 구성
– Master NameNode : 파일시스템 이미지(fsimage)와 변경 기록(edits)을 저장
• fsimage는 in-memory로 관리됨
– Secondary NameNode : Master NameNode의 fsimage 파일과 edits 파일의 사본을 저장
– DataNode : 데이터 파일의 블록을 저장, 디폴트 블록의 크기는 128MB
• 저렴한 컴퓨터로 대용량 데이터를 저장할 수 있는 시스템
– 네트워크 Raid와 같이 연결된 것처럼 사용하는 하드디스크
– Scale Out
• Block(Chunk) 단위로 파일 관리 (저장/복제/삭제)
– Default Size는 128M(134217728)
• 복제 기능을 통해 안전성/신뢰성을 보장
• 1대의 Master서버에 4000+이상의 DataNodes를 운영할 수 있음.
• API 지원
HDFS는 높은 장애 결함 허용성(내결함성)을 제공하고, 저비용의 범용 하드웨어 기반으로도 효율적인 분산 파일 시스템 구성 가능하며, 고가용성(High-availability)을 위하여 대용량의 데이터를 미리 정해진 크기의 단위로 구성 노드들에게 분산 저장하여 기본적으로 3개의 데이터 노드에 중복으로 데이터를 저장하기 때문에 대용량의 데이터를 안정적으로 관리할 수 있다.
HDFS의 네임 노드(Name node)와 하나 이상의 데이터노드(Data node)로 구성되며 이는 각각 마스터 노드(Master ndoe) ,슬레이브 노드(Slave node)라고 불리기도 한다.
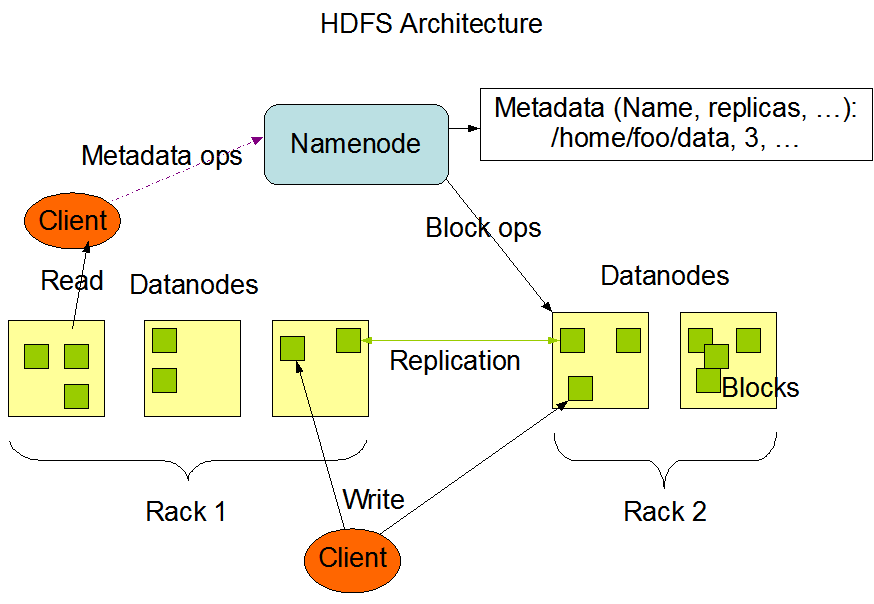
HDFS을 구성하는 또 다른 노드인 데이터 노드는 분산 처리할 정보가 실제 저장되는 노드로써, 위 그림과 같이 여러 데이터 노드가 하나의 Rack으로 묶여있다. 원래 Rack은 데이터 센터에서 서버 등의 다양한 장비들을 효율적으로 장착하기 위한 프레임을 의미하는 용어이지만, HDFS에선 데이터의 복사본을 배치할 때 고려하는 요소로써 사용된다.
HDFS에선 데이터를 저장할 때 파일 시스템 클라이언트로부터의 요청 및 디렉터리 생성/삭제/조회 등의 작업이 데이터 노드에서 실행되게 되는데, 기본적으로 데이터의 블록단위 분할처리 이후 각 블록마다 두 개의 복사본을 생성해 원본 블록을 포함하여 총 세 개의 동일한 블록을 유지하도록 한다. 데이터 노드는 데이터를 저장할 때 첫 번째 블록이 저장되지 않은 Rack을 찾아 그 Rack에 포함된 데이터 노드 두 개를 조회하여 두 번째와 세 번째 복제된 블록을 저장하는 방식을 사용한다. 이를 통해 특정 Rack 전체가 문제가 생기더라도 다른 Rack에서 해당 데이터를 구성하는 블록을 찾을 수 있기 때문에 HDFS의 데이터 신뢰성을 높이는 핵심적인 기능이다.
HDFS의 데이터 신뢰성을 유지하는 기능은 데이터 노드뿐 만 아니라 데이터 노드를 관리하는 네임 노드에서도 제공한다. 네임 노드는 주기적으로 클러스터의 각 데이터 노드에서 하트비트, 즉 이 노드가 활동 중인지 아닌지에 대한 정보를 수신한다. 하트 비트를 수신하면 데이터 노드가 제대로 작동하고 있음을 나타내며, 만약 네임 노드가 특정 데이터 노드로부터 하트 비트를 수신받지 못했다면, 네임 노드는 해당 데이터 노드를 사용불가 상태로 등록하고, 해당 데이터 노드에 저장되어 있던 복제 본을 다른 데이터노드에 복제하여 블록의 복제본 개수를 기존 개수와 동일하도록 관리하는 기능을 제공한다.
하둡에 대해서 나름 정리를 하다 보니 예전에 구축했었던 하둡 클러스터를 조금 더 성능 튜닝을 해보고 싶어 졌다. 다음 글에선 실제로 하둡 환경을 구축하여 테스트해본 결과를 포스팅해볼 예정이다.