
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- container
- big data
- Apache kafka
- docker desktop
- Django
- wsl2
- 하둡
- 이미지
- Kafka
- docker-compose
- nginx
- docker
- Docker #도커 #이미지 #컨테이너 #리눅스 #Back-end
- topic
- 데이터 수집
- Window 10
- Dockerfile
- hadoop
- 빅데이터
- Jupyter notebook
- hyper-v
- orchestration
- 도커
- hdfs
- Today
- Total
개발자 일기장
[Kafka #1/kafka 시작하기] 본문

카프카란?
아파치 카프카는 2011년 미국 링크드인(Linkedin)에서 개발되어 최종적으로 아파치 재단에 오픈소스화 되었고, 현재는 카프카에 집중하기 위해서 Confluent 라는 이름으로 카프카에 대한 서비스를 운영하고있다.
카프카는 RabbitMQ, ZeroMQ 와 함께 자주 거론되는 메세지 큐 시스템이다. 하둡 에코시스템에 포함되어있으며, 대용량의 실시간 로그처리에 특화되어 있는 솔루션이며 데이터를 유실없이 안전하게 전달하는 것이 주목적인 메세지 시스템에서 Fault-Tolerant(기능 장애 상태를 유지하더라도 성능을 저하시키지 않고 가동하는)한 안정적인 아키텍처와 빠른 퍼포먼스로 데이터를 처리할 수 있다. 카프카는 다른 하둡 에코 시스템들과의 호환성도 상당히 높은 편이여서 데이터 수집에서는 카프카가 많이 사용된다.
사용사례
LinkedIn : activity streams, operational metrics, data bus(400 nodes, 18k topics, 220B msg/day in May 2014)
Netflix : real-time monitoring and event processing
Twitter : as part of their Storm real-time data pipelines
Spotify : log delivery, Hadoop
11번가 : 카프카를 이용한 비동기 주문시스템(카프카 컨슈머 애플리케이션 배포 전략 medium post)
LINE : LINE에서 Kafka를 사용하는 방법 - 1(engineering.linecorp.com/ko/blog/how-to-use-kafka-in-line-1/)
카프카 특징
- Pub-Sub 모델 :
Pub-Sub 모델, 즉 발행-구독 모델은 Publisher-Subscriber 구조를 말하며, 메세지 큐를 기반으로 하여 양쪽에서 독립적으로 데이터를 생산하고 소비한다.
이런 느슨한 결합(느슨한 결합은 "Loosely Coupled" 라고도 불리며, 하나의 컴포넌트의 변경이 다른 컴포넌트의 변경을 요구하는 위험을 줄이는 것을 목적으로 하는 시스템으로써 컴포넌트간의 내부 의존성을 줄이므로써 전체 프레임워크를 안정적으로 유지한다.)을 통해 Publisher나 Subscriber가 다운되더라도, 서로 간에 의존성이 없으므로 안정적으로 데이터를 처리할 수 있다. - 고가용성(HA : High availability) 및 확장성(Scalability) :
카프카는 클러스터로서 작동한다. 클러스터로서 작동하므로 Fault-tolerant 한 고가용성 서비스를 제공할 수 있고 분산 처리를 통해 빠른 데이터 처리를 가능하게 한다. 또한 서버를 수평적으로 늘려 안정성 및 성능을 향상시키는 Scale-out이 가능하며, 단일의 카프카도 클러스터로써 작동된다 . - 디스크 순차 저장 및 처리(Sequential Store and Process in Disk) :
기존 메세지 시스템은 메세지를 메모리 큐에 적재하지만, 카프카는 메세지를 디스크에 순차 저장하므로써 다음과 같은 이점을 갖는다.
1. 서버에 장애가 나도 메세지가 디스크에 저장되어 있으므로 유실걱정이 없음
2. 디스크가 순차적으로 저장되어 있으므로 디스크 I/O가 줄어들어 성능향상 - 분산 처리(Distributed Processing) :
카프카는 파티션(Partition)이란 개념을 도입하여 여러개의 파티션을 서버 내의 아파치 주키퍼(Apache Zookeeper)를 통해 분산 처리하므로써 메세지를 상황에 맞추어 빠르게 처리할 수 있다.
카프카의 구조
프로듀서(producer)와 컨슈머(consumer), 브로커(broker)로 구성된다. 아래 그림은 카프카의 구성을 보여준다.
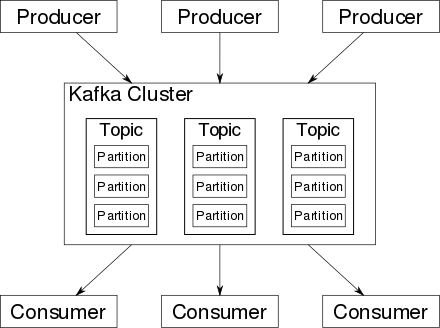
카프카의 데이터 기본 단위는 메시지(message)로 데이터베이스의 행(row)이나 레코드(record)에 비유된다. 또한 카프카의 메시지는 토픽(topic)으로 분류되는데, 이는 데이터베이스 테이블이나 파일 시스템의 폴더와 동일한 개념을 가진다.
프로듀서가 특정 토픽의 메시지를 생성한 뒤 브로커에 전달하면, 브로커는 메시지를 토픽별로 분류하여 쌓아놓는다. 그리고 해당 토픽을 구독하는 컨슈머들이 메시지를 가져가서 처리하게 된다.
카프카의 토픽은 파티션(Partition)이라는 단위로 구성되어 메시지의 처리는 토픽이 아닌 파티션별로 관리가 된다. 아래 그림은 1개의 토픽이 3개의 파티션에 분산되어 있는 것을 보여주며 추가되는 메시지는 각 파티션의 끝에 적재된다.

위 그림과 같이 파티션은 0부터 1씩 증가하면서 오프셋(offset) 값을 메시지에 부여하는데 이 값은 개별 파티션 내에서 메시지 식별 ID로 사용되며, 토픽 내에서 메시지를 식별할 때에는 파티션 값과 오프셋 값을 함께 사용해야 한다.
카프카의 파티션은 오직 1개의 컨슈머의 접근만을 허용하며, 컨슈머의 개수가 파티션의 개수보다 작으면 하나의 컨슈머가 여러 개의 파티션을 소유하게 되고, 반대로 컨슈머의 개수가 파티션의 수보다 많으면 여분의 컨슈머는 메시지를 처리하지 않게 되므로 조정이 필요하다.

만약 컨슈머 그룹 안의 컨슈머가 파티션의 개수와 같다면 컨슈머는 파티션과 1:1 매칭이 되지만, 컨슈머의 개수가 파티션의 개수보다 적을 경우 컨슈머 중 하나가 매칭되지 않은 파티션의 데이터를 처리하게 된다. 또한, 이와 반대로 컨슈머의 개수가 파티션의 개수보다 많을 경우 매칭되지 않은 컨슈머는 파티션의 개수가 추가될때까지 대기하게 된다.
카프카에 대해서 간단하게 개념 파악 및 역할을 알아보았으므로 다음 포스팅에선 싱글 카프카를 구축하여 데이터를 받아보는 예제를 포스팅 할 예정이다.
출처:
https://engkimbs.tistory.com/691
[Kafka, 카프카] 아파치 카프카(Apache Kafka) 아키텍처 및 동작방식, 파티션 읽기 쓰기(Partition Read and W
| 카프카(Kafka)란? 아파치 카프카(Apache Kafka)는 분산 스트리밍 플랫폼이며 데이터 파이프 라인을 만들 때 주로 사용되는 오픈소스 솔루션입니다. 카프카는 대용량의 실시간 로그처리에 특화되어
engkimbs.tistory.com
빅 데이터 처리를 위한 아파치 Kafka 개요 및 설명
Apache Kafka LinkedIn에서 최초로 만들고 opensource화 한 확장성이 뛰어난 분산 메시지 큐(FIFO : First In First Out) → 분산 아키텍쳐 구성, Fault-tolerance한 architecture(with zookeeper), 데이터 유실..
blog.voidmainvoid.net